
※ この記事にはアフィリエイトリンクが含まれています。詳細はプライバシーポリシーをご確認ください。
「ChatGPTに長い資料を貼ったらエラーが出た」「Claudeで会話を続けていたら急に挙動が変になった」──多くのエンジニアが経験する現象です。正体はほぼすべて、コンテキストウィンドウの上限に関係しています。
Claude Opus 4.7の1Mトークンや Gemini 1.5 Proの2Mトークンといった大容量化が進んでいますが、「大きいから全部入れれば良い」は最大のアンチパターンです。コストが10倍に跳ね、Lost-in-the-Middleで精度も落ちる二重損失になります。
この記事は、コードが書けるエンジニア向けにコンテキストウィンドウを実装視点で整理します。トークンの仕組みから主要LLMの容量比較、長文を扱うときの分割戦略、そしてLost-in-the-Middle問題までコード付きで解説します。
僕は普段、Claude CodeやCursorを毎日使い、自動化スクリプトをLLMで動かしています。その中で「context window が大きいから全部突っ込めば良い」と思って痛い目を見たことが何度もあります。本記事はそこで得た「処理量の上限と付き合う型」をまとめた実装ガイドです。
本記事はAI学び直し|エンジニアの実務スキル4階層のシリーズ第2回(第1階層:生成AI活用)にあたります。前回のプロンプトエンジニアリング入門とあわせて読むと理解が早まります。
こんな方に読んでほしい
- OpenAI/Anthropic APIを使っていて「トークン上限エラー」に遭遇したことがある方
- 長文ドキュメントをLLMに食わせる業務スクリプトを書きたい方
- 主要モデルのコンテキストウィンドウ容量を実務目線で比較したい方
- 会話履歴の管理やチャンク分割の実装パターンを知りたい方
コンテキストウィンドウとは何か
結論:LLMが一度に処理できる入出力の上限
コンテキストウィンドウとは、LLMが1回のリクエストで扱える入力+出力の合計トークン数の上限です。「短期記憶の容量」と例えられることが多い概念です。
注意点は、これが入力だけの上限ではなく、入力と出力の合計を指すことです。入力で上限ギリギリまで使うと、出力できる余地がなくなります。
なぜエンジニアがこれを意識する必要があるのか
Web UIで使う分には、ユーザー側があまり気にしないことが多いです。しかしAPI経由でLLMをコードに組み込むと、上限を超えた瞬間にエラーが返ります。
具体的には次のような場面で必ず効いてきます。
- 長文ドキュメント要約:1万字のPDFを丸ごと投げると上限に近づく
- 会話アプリ:履歴を積むほど入力トークンが増えてコストが膨らむ
- RAG(検索拡張生成):取得チャンクを盛りすぎると上限に到達する
- コード生成:大きなファイルを参照させると一瞬で枯渇する
つまり実務でLLMを使うほぼすべての場面で、上限と付き合う設計が求められます。
トークンの仕組みと計測方法
トークンとは「文字数」ではない
コンテキストウィンドウの単位はトークンであり、文字数とは一致しません。トークンはモデル内部で文字列を分割した最小単位を指します。
英語と日本語ではトークン化の効率が大きく異なります。経験的な目安は次の通りです。
- 英語:1トークン ≒ 0.75単語(4文字程度)
- 日本語:1トークン ≒ 1〜2文字(漢字は1〜2文字、ひらがなは1文字程度)
同じ意味を伝える文章でも、日本語のほうがトークン数が多くなりがちです。日本語1万字なら、おおむね5,000〜10,000トークン前後と見積もります。
tiktokenでトークン数を計測する
OpenAIモデルのトークン数は、tiktokenライブラリで正確に計測できます。実装は最小限で書けます。一次情報はOpenAI TokenizerのWeb版で対話的に確認できるので、ライブラリと併用すると感覚がつかみやすくなります。
import { encoding_for_model } from "tiktoken";
const enc = encoding_for_model("gpt-4o");
function countTokens(text: string): number {
return enc.encode(text).length;
}
const sample = "こんにちは、これは日本語のサンプル文章です。";
console.log(countTokens(sample)); // 例: 18トークン
// 使用後はメモリ解放
enc.free();事前にトークン数を測れば、上限に対してどれくらい余裕があるかを定量的に把握できます。Anthropic(Claude)の場合はanthropic.messages.countTokens()でAPI経由の計測が可能です。
1トークンあたりのコスト感
API利用ではトークン数がそのままコストに直結します。2026年時点の概ねの相場は次のレンジです(最新値は公式の料金ページで都度確認してください)。
- GPT-4o系:入力 $2.5/100万トークン、出力 $10/100万トークン前後
- Claude 3.5 Sonnet系:入力 $3/100万トークン、出力 $15/100万トークン前後
- Gemini 1.5 Pro系:入力 $1.25/100万トークン、出力 $5/100万トークン前後
1ドル≒150円換算で、1万トークン入力あたり数円程度です。一見安く見えますが、長文を毎日大量に処理するスクリプトでは月数万円に膨らむこともあります。
主要LLMのコンテキストウィンドウ比較
2026年時点で実務に使われる主要モデルの容量は、おおむね次の通りです。新モデルが頻繁に出るため、必ず公式ドキュメントで最新値を確認してください。
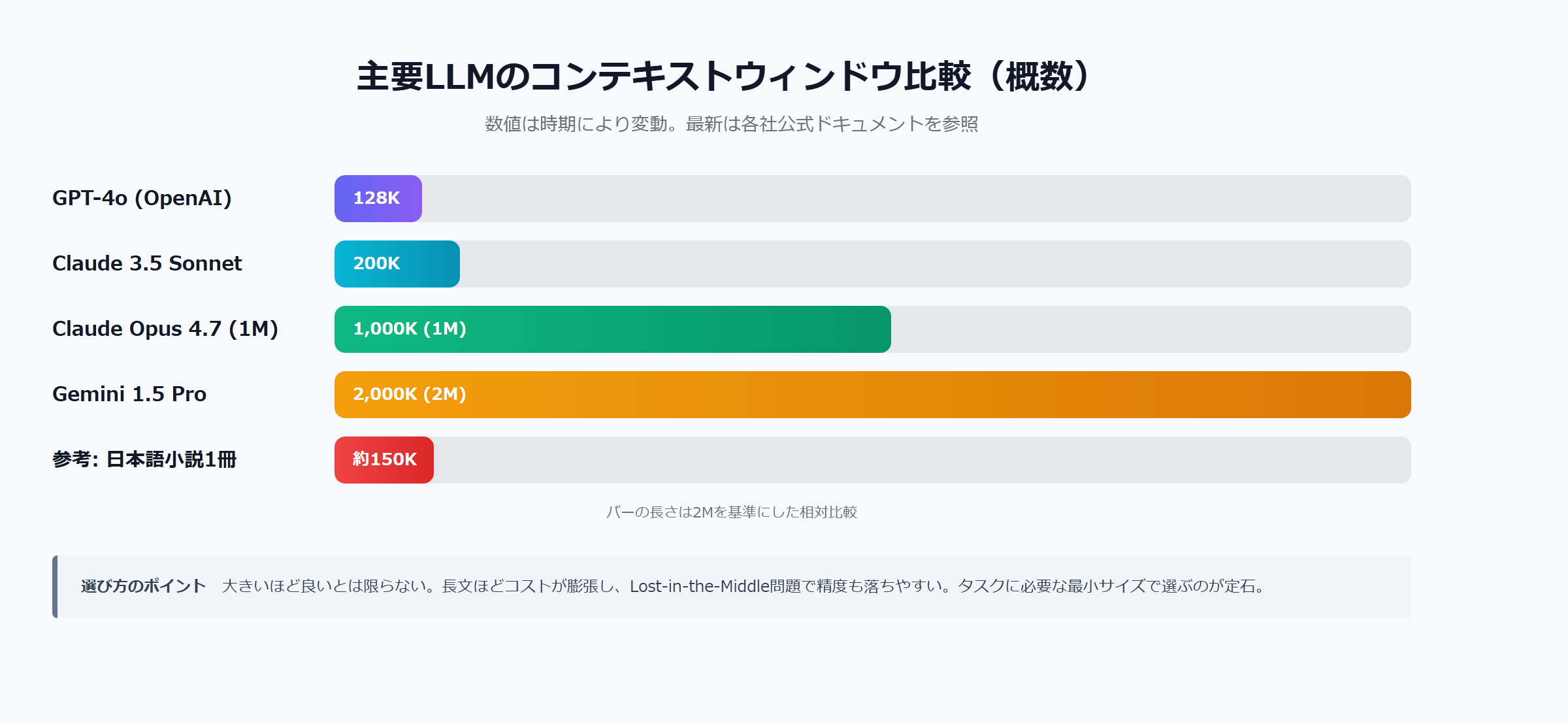
容量と用途のマッピング
| モデル | 概ねの容量 | 主な用途 |
|---|---|---|
| GPT-4o | 128Kトークン | 汎用タスク、中規模ドキュメント |
| Claude 3.5 Sonnet | 200Kトークン | コード解析、長文要約 |
| Claude Opus 4.7(1Mプラン) | 1Mトークン | 巨大コードベース、書籍丸ごと |
| Gemini 1.5 Pro | 最大2Mトークン | 超長文、動画文字起こし解析 |
200Kトークンは日本語で概ね15〜20万字、1Mトークンなら70〜100万字に相当します。ただし「容量が大きい=何でも放り込める」ではない点が、次のセクションのテーマです。
容量が大きいモデルを選ぶ基準
大容量モデルは便利ですが、コストと速度のトレードオフがあります。判断基準は次のようになります。
- 大容量を選ぶべき:複数ファイルを横断的に解析する/長い会話履歴を保持したい
- 標準容量で十分:単発の要約/分類/変換タスクが中心
- 小型モデルで十分:定型処理のバッチ実行で速度・コストを優先
業務で使うなら、まず標準容量のモデルでプロトタイプを作り、必要になってから大容量モデルへ切り替えるのが定石です。最初から1Mトークンを使うと、設計の甘さがコストとして跳ね返ってきます。
長文を扱うための実装パターン
戦略1:チャンク分割で段階的に処理する
上限を超えそうな長文は、意味のある単位で分割し、各チャンクを個別処理してから統合するのが基本です。最小実装は次の通りです。
function splitIntoChunks(text: string, maxChars = 4000): string[] {
const chunks: string[] = [];
const paragraphs = text.split(/\n\n+/);
let buffer = "";
for (const p of paragraphs) {
if ((buffer + p).length > maxChars) {
if (buffer) chunks.push(buffer);
buffer = p;
} else {
buffer += (buffer ? "\n\n" : "") + p;
}
}
if (buffer) chunks.push(buffer);
return chunks;
}
// 使い方
const chunks = splitIntoChunks(longDoc, 4000);
const summaries = await Promise.all(
chunks.map((c) => summarize(c))
);
const finalSummary = await summarize(summaries.join("\n\n"));段落単位で区切る点がポイントです。文字数だけで機械的に切ると、文の途中で切れて意味が壊れます。MarkdownならH2/H3で、コードなら関数単位で区切るとより精度が出ます。
戦略2:会話履歴を自動で刈り込む
チャットアプリ系のスクリプトでは、履歴を無制限に積むと上限に到達します。古いメッセージから順に削除する刈り込み関数を1つ用意しておくと安全です。
type Message = { role: "user" | "assistant"; content: string };
function trimHistory(
messages: Message[],
maxTokens: number,
countFn: (s: string) => number
): Message[] {
// 直近のメッセージから残す
const reversed = [...messages].reverse();
const kept: Message[] = [];
let total = 0;
for (const m of reversed) {
const t = countFn(m.content);
if (total + t > maxTokens) break;
kept.push(m);
total += t;
}
return kept.reverse();
}
// 使い方(上限の70%で刈り込み)
const trimmed = trimHistory(history, 128_000 * 0.7, countTokens);上限の70〜80%で刈り込むのが経験的に安定します。100%ギリギリまで使うと、出力余地がなくなって応答が途切れる事故が起きます。
戦略3:context長の事前見積もりとコスト計算
本番投入前に、1リクエストあたりの想定トークン数とコストを計算しておくと事故が減ります。
type CostConfig = {
inputPricePerM: number; // $/1Mトークン
outputPricePerM: number;
};
function estimateCost(
inputTokens: number,
outputTokens: number,
cfg: CostConfig
): { usd: number; jpy: number } {
const usd =
(inputTokens / 1_000_000) * cfg.inputPricePerM +
(outputTokens / 1_000_000) * cfg.outputPricePerM;
return { usd, jpy: Math.round(usd * 150) };
}
// GPT-4oで入力5万トークン・出力2千トークンの想定
const c = estimateCost(50_000, 2_000, {
inputPricePerM: 2.5,
outputPricePerM: 10,
});
console.log(c); // { usd: 0.145, jpy: 22 }1回数十円でも、月1万回叩けば数十万円です。バッチ処理を組むときは、必ず1件あたりのコストを計算してから走らせます。
戦略4:Lost-in-the-Middle問題への対処
長いcontextを与えると、中盤に置かれた情報の参照精度が落ちる現象が知られています。これがLost-in-the-Middle問題です。詳細はAnthropic Long context tipsなどで触れられており、長文を扱う実装で必ず意識しておきたい性質です。
対処の定石は次の3つです。
- 重要情報は冒頭か末尾に置く:システムプロンプトの先頭、もしくはユーザー指示の直前
- 要約してから渡す:生のチャンクではなく、各チャンクの要約を結合する
- RAGで関連箇所だけ抽出:埋め込みベクトル検索で関連度の高い部分だけ渡す
3番目のRAGについては次回の記事で扱います。Embedding/埋め込みベクトルの基礎を押さえると、長文処理の選択肢が広がります。
よくある失敗パターン
実装初期に必ずと言っていいほどハマる失敗例を3つ並べます。事前に知っておくと回り道を減らせます。
失敗1:「容量が大きいから全部入れる」でコスト爆発
1Mトークンモデルが出てきた頃、僕も「資料を全部投げれば良い」と考えました。結果、1リクエスト数百円の処理が積み重なり、想定外のコストになりました。
容量があることと、容量を使うべきことは別物です。必要な部分だけ抜き出して渡すほうが、精度もコストも改善します。RAGや事前要約を併用するのが定石です。
失敗2:Lost-in-the-Middle問題を知らずに精度低下
「200Kトークン全部使えば、最後に書いた指示も拾ってくれるはず」と期待すると裏切られます。中盤の情報は取りこぼされる前提で設計するのが安全です。
具体的には、重要な指示や制約はシステムプロンプトの先頭か、ユーザーメッセージの末尾に置きます。中盤に長い参考資料を挟む構成にすると、指示が埋もれます。
失敗3:会話履歴を無制限に積んで上限到達
チャットUIを実装したあと、履歴の刈り込みを入れ忘れて本番で詰まる事故は鉄板です。10往復もすれば、簡単に数万トークンに到達します。
対処は前述のtrimHistory関数を最初から組み込んでおくことです。「あとで入れる」ではなく、最初の実装で組み込むのが定石です。
もっと深く学ぶなら、シリーズで全体像を掴む
コンテキストウィンドウは「LLMをコードに組み込むときの基礎体力」にあたる概念です。プロンプト設計の理解と組み合わせると、長文・会話・RAGなど複数のシナリオに応用が効きます。
体系的に学ぶなら、本シリーズの親記事であるAI学び直し|エンジニアの実務スキル4階層を起点に、関連記事を順に読むのがおすすめです。
第1階層「生成AI活用」の3テーマ(プロンプト・コンテキスト・Embedding)が土台です。これを押さえてから第2階層以降の自動化・エージェント設計に進むのが効率的です。
独学のステップを踏んだあと、より実務寄りに学びたい場合は前回記事のCTAも参考にしてください。本記事ではアフィリ抜きで、シリーズの内部動線だけにとどめます。
シリーズの位置づけと次回予告
本記事はAI学び直し|エンジニアの実務スキル4階層シリーズの第2回です。第1階層「生成AI活用」のうち、LLMの処理上限であるコンテキストウィンドウを取り上げました。
次回(5月4日公開予定)は、Embedding/埋め込みベクトルを扱います。長文を扱うときの「関連箇所だけ抽出する」仕組みの中核技術で、RAGの基礎にもなります。本記事と直接つながる内容なので、続けて読むと理解が深まります。
まとめ|上限と付き合う設計が実務の鍵
コンテキストウィンドウは「処理できる量の上限」を意味し、入力+出力の合計トークン数で決まります。容量はモデルによって128K〜2Mトークンまで幅があり、用途に応じて選びます。
長文を扱うときは、チャンク分割/会話履歴の刈り込み/コスト見積もり/Lost-in-the-Middle対策の4つを基本パターンとして押さえます。容量が大きいから全部入れる、という発想はコストと精度の両面で裏目に出ます。
明日からの実務では、まずtiktokenでトークン数を測ることから始めてみてください。「自分のリクエストが何トークンを消費しているか」が見えるだけで、設計の解像度が一段上がります。
進展があったらこのブログで共有します。長文処理パイプラインや会話履歴の永続化戦略についても、できたら定点観測の記事を書いてみたいと考えています。


コメント