
※ この記事にはアフィリエイトリンクが含まれています。詳細はプライバシーポリシーをご確認ください。
「AIエージェント」という言葉は2026年に入って一気に主流になりましたが、実装の中身は驚くほどシンプルです。Function Callingをループさせるだけで土台は出来上がります。コードに落とすと本質はwhile文3行に収まります。
抽象的な解説記事を読むより、Anthropic SDKやOpenAI SDKを直接叩いて動かすほうが、ずっと早く理解できる領域です。
この記事は、コードが書けるエンジニア向けにAIエージェントの実装パターンを整理します。最小Agentループ、Plan-Execute、停止条件、メモリ設計までコード付きで解説します。「自律実行」を魔法ではなく実装として理解するのが目的です。
僕は普段、Claude CodeやCursorをエディタとして毎日使い、自動化スクリプトを書いています。Agent的な処理を組み込むときに最初に詰まったのが「停止条件」と「ツール失敗時のリトライ」でした。本記事はそこで学んだことを整理した実装ガイドです。
本記事はAI学び直し|エンジニアの実務スキル4階層のシリーズ第6回(第3階層:AIアプリ開発)にあたります。前回はFunction Calling入門を扱いました。今回はその応用編として、Function Callingを「ループさせる」Agentの実装に踏み込みます。
こんな方に読んでほしい
- Function CallingをAPIで叩けるようになり、次に何をすべきか迷っている方
- AIエージェントの実装パターンを、抽象論ではなくコードで理解したい方
- LangChainやCrewAIのようなフレームワークを使う前に、中身を理解したい方
- 自律実行ロジックを業務スクリプトに組み込みたいエンジニア
AIエージェントとは何か
結論:LLMがツールを使い自律的にタスクを進める仕組み
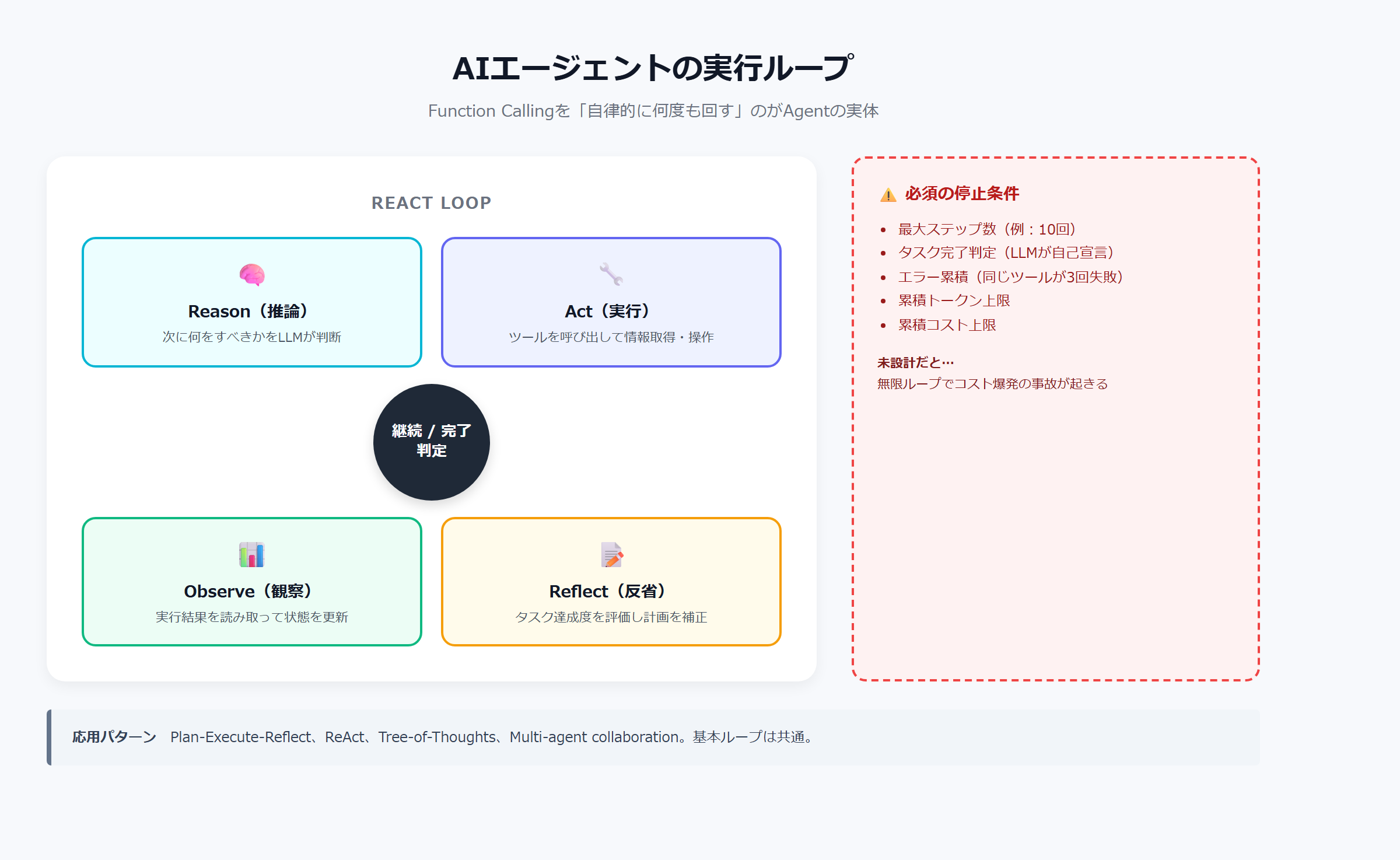
AIエージェントとは、LLMがツールを使い、結果を観察し、次の行動を判断しながらタスクを進める仕組みです。1回のAPI呼び出しで完結する通常のチャットと違い、複数ステップを自律的に回します。
実装の中身は驚くほどシンプルです。Function Callingで返ってきたツール呼び出しを実行し、結果をLLMに戻し、再度LLMに次の行動を判断させる。このループの繰り返しが本体です。
各社の公式ガイドが一次情報として最も信頼できます。Anthropic Agents and toolsとOpenAI Assistants Overviewを併読すると、両社の設計思想の違いが見えてきます。
「自律実行」の正体は単なるループ
世の中のAgent記事は抽象的な説明が多いですが、コードに落とすと拍子抜けするほど単純です。
// Agentの本質はこの3行
while (!done) {
const action = await llm.decide(state); // 次に何をするか判断
const result = await execute(action); // ツールを実行
state = update(state, action, result); // 状態を更新
}このループにツール定義・停止条件・メモリを足したものがAIエージェントです。フレームワークは便利ですが、最初から使うと中身が見えなくなります。まず素のループで動かすのが理解の近道です。
Function CallingからAgentへの拡張
違いは「ループするかどうか」だけ
Function Callingは「LLMがツールを呼び出すための仕組み」です。Agentは「Function Callingを停止条件まで繰り返す仕組み」です。差はそれだけです。
1回のFunction Callingでは、LLMが1つのツール呼び出しを返して終わります。Agentは結果を受け取り、必要なら次のツール呼び出しを返し、また実行する、を繰り返します。
ReActパターン:推論と行動の交互実行
初期のAgent論文で広まったのがReAct(Reason+Act)パターンです。LLMに「考える(Reason)→行動する(Act)→観察する(Observe)」を交互に出力させる手法です。
現代のFunction Calling対応モデルでは、ReActを明示的にプロンプトで誘導しなくても、内部で同等のことを行います。重要なのはパターン名ではなく、「ツール結果をLLMに戻す」サイクルを理解しておくことです。
Plan-Execute:計画と実行を分離する
もう一つよく使われるのがPlan-Executeパターンです。最初にLLMに全体計画を立てさせ、その計画に沿ってステップを順次実行します。
ReActが「考えながら歩く」のに対し、Plan-Executeは「先に地図を引いてから歩く」イメージです。タスクが複雑で、途中の方針ブレを避けたい場面で効きます。後ほど実装例を示します。
実装パターン(最小/Plan-Execute/停止条件)
最小Agentループの実装
まずは素のFunction Callingをwhileで回すだけの最小Agentを書きます。前回記事のFunction Callingコードに、ループと停止条件を加えるだけです。
// 最小Agentループ
async function runAgent(userTask: string, maxSteps = 10) {
const messages: Message[] = [
{ role: "system", content: "ツールを使ってタスクを完了してください。" },
{ role: "user", content: userTask },
];
for (let step = 0; step < maxSteps; step++) {
const res = await llm.chat({
messages,
tools: toolDefinitions,
});
messages.push(res.message);
// ツール呼び出しがなければ完了
if (!res.tool_calls || res.tool_calls.length === 0) {
return res.message.content;
}
// ツールを実行して結果を戻す
for (const call of res.tool_calls) {
const result = await executeTool(call.name, call.arguments);
messages.push({
role: "tool",
tool_call_id: call.id,
content: JSON.stringify(result),
});
}
}
throw new Error("最大ステップ数に到達しました");
}20行ほどでAgentの土台が動きます。ポイントはツール呼び出しがなければループを抜ける点と、maxStepsで暴走を防ぐ点です。
Plan-Execute実装:計画段階と実行段階を分離する
複雑なタスクでは、最初に計画を立ててから実行するほうが安定します。計画段階は推論特化モデル(o3やClaude Opus)、実行段階は安価なモデル(Haikuなど)に分けるとコスト効率も上がります。
// Plan-Execute実装
async function planAndExecute(userTask: string) {
// ステップ1:計画を立てる
const planRes = await llm.chat({
model: "claude-opus-4-7",
system: "タスクをサブステップに分解してください。" +
"JSON配列で返してください: [{step: 1, action: '...'}]",
user: userTask,
response_format: { type: "json_object" },
});
const plan = JSON.parse(planRes.content).steps;
// ステップ2:各サブステップを実行
const results = [];
for (const subStep of plan) {
const res = await runAgent(subStep.action, 5);
results.push({ step: subStep.step, output: res });
}
// ステップ3:結果を統合
return await llm.chat({
system: "実行結果を統合して最終回答を作成してください。",
user: JSON.stringify(results),
});
}計画と実行を分離すると、ステップ単位でデバッグできるのが大きな利点です。途中で結果が想定外なら、その段階の入出力だけを見ればよく、ログ追跡が楽になります。
停止条件とエラーハンドリング
本番運用では、停止条件とエラー処理が品質と安全性の両方を支えます。最低限、次の3つは必ず実装します。
- 最大ステップ数:暴走対策(例:10〜20ステップで強制終了)
- タスク完了判定:LLMが「完了」を示すツールを呼んだら終了
- ツール失敗時の再試行:1回の失敗でループ全体を止めない
// エラーハンドリング付きツール実行
async function executeToolSafe(name: string, args: any, retries = 2) {
for (let i = 0; i <= retries; i++) {
try {
return await executeTool(name, args);
} catch (err) {
if (i === retries) {
// 最終的に失敗したらLLMにエラー内容を戻す
return { error: String(err), retried: i };
}
await new Promise(r => setTimeout(r, 1000 * (i + 1)));
}
}
}ツールが失敗したときは、エラー内容をそのままLLMに戻すのが定石です。LLMは「前のツールが失敗したから別のアプローチを試す」と判断できます。例外で即停止するより、はるかに頑健になります。
メモリとヒューマン・イン・ザ・ループ
短期メモリと長期メモリの使い分け
Agentにメモリを持たせると、ステップ間で情報を保持できます。実装の粒度は2種類あります。
- 短期メモリ:現在の会話履歴(messages配列)。コンテキストウィンドウに収まる範囲
- 長期メモリ:ベクトルDB(PineconeやChromaなど)に保存。過去のセッションや知識を参照
短期メモリはmessages配列をそのまま使えば成立します。長期メモリが必要になるのは、過去のセッション結果を参照したい場面や、社内ドキュメントを検索しながら回答するRAGと組み合わせる場面です。
初学者は最初から長期メモリを設計しがちですが、まずは短期メモリだけで動かし、必要性が見えてから長期メモリを足すほうが事故が少ないです。
ヒューマン・イン・ザ・ループで安全性を担保する
業務でAgentを動かすとき、破壊的操作の前に人間に確認を求める仕組みは必須です。ファイル削除・メール送信・本番DB更新など、取り消せない操作はとくに注意します。
// 危険な操作前に承認を求める
async function executeWithApproval(call: ToolCall) {
const dangerousTools = ["delete_file", "send_email", "execute_sql"];
if (dangerousTools.includes(call.name)) {
console.log(`実行予定: ${call.name}(${JSON.stringify(call.arguments)})`);
const approved = await askUser("実行しますか? (y/n)");
if (!approved) {
return { skipped: true, reason: "ユーザーが承認しませんでした" };
}
}
return await executeTool(call.name, call.arguments);
}「Agentに全部任せる」は危険です。判断はAgent、実行の最終承認は人間、という分担が現実的です。承認のオーバーヘッドが運用上問題なら、ホワイトリスト型ツール(読み取り系のみ)から順に自動化していきます。
よくある失敗パターン
初学者がAgent実装で踏みやすい失敗パターンを3つ並べます。事前に知っておくと事故を減らせます。
失敗1:停止条件が未設計で無限ループ
maxStepsを設定せずに動かすと、LLMが同じツールを呼び続けてコストが爆発するケースがあります。僕も最初の検証で1回数百円のリクエストを出したことがあり、停止条件の重要性は身に染みています。
対策はシンプルで、必ず最大ステップ数を設定することです。さらに、同じツールを連続3回呼んだら警告を出すような追加ロジックも有効です。コスト上限(円換算で月◯◯円まで)でハードストップを入れておくと、暴走時の被害が最小化されます。
失敗2:エラーハンドリング無しでツール失敗時に止まる
ツール(外部API・DB・ファイル操作)は失敗します。例外をキャッチせずにthrowすると、Agent全体が止まります。一時的なネットワーク失敗で全停止するのは運用上きついです。
前述のexecuteToolSafeのように、エラーをLLMに戻す設計にすれば、Agentが代替手段を試す余地が生まれます。LLMは「前のツールが失敗した」を理解して別のアプローチを取れます。
失敗3:「全部Agentで自動化」の過信
Agentは万能ではありません。判断ミス・指示の取りこぼし・ツール選択の間違いを必ず起こします。ヒューマン・イン・ザ・ループ無しで本番運用すると事故ります。
とくに取り消せない操作(メール送信・本番DB更新・課金処理)は人間の承認を挟むのが原則です。「便利」と「安全」のバランスは設計者が引き受ける部分です。
運用視点でもう一つ重要なのが観測性です。Agentの各ステップで「LLMの判断・呼び出したツール・引数・実行結果」を構造化ログに残しておくと、事後の原因分析が可能になります。トレース可視化ツール(LangSmith等)を入れると一段楽になりますが、最初は自前のJSONログで十分です。
もっと深く学ぶなら
Agent実装は独学で詰まる人が多い領域です。体系化されたカリキュラムで進めたいなら、DMM WEBCAMP 学習コースが選択肢の一つになります。現職を続けたままスキルだけ獲得したい方に向きます。
- デメリット:受講料が他の独学型より明確に高い
- メリット:体系化されたカリキュラム/メンター伴走でつまずき箇所を早く突破できる
シリーズの位置づけと次回予告
本記事はAI学び直し|エンジニアの実務スキル4階層シリーズの第6回です。第3階層「AIアプリ開発」の入口として、AIエージェントを取り上げました。
前回はFunction Calling入門でツール呼び出しの基本を扱いました。本記事はそれを「ループさせる」発展編にあたります。
次回(5月8日公開予定)は、Agentの拡張として広がっているMCP(Model Context Protocol)を扱います。AnthropicがオープンソースとしてリリースしたAgent向けのツール接続プロトコルで、ツール実装の標準化に効きます。
まとめ|Agentの本体はFunction Callingのループ
AIエージェントの本質は、Function Callingを停止条件まで繰り返すループです。フレームワークを使う前に、素のwhileループで動かすと中身が腑に落ちます。
実装で必須なのは3点です。最大ステップ数による暴走防止、ツール失敗時のエラー戻し、破壊的操作のヒューマン承認。この3つを押さえると、業務に組み込んでも事故りにくいAgentになります。
明日からの実務で、まず最小Agentループ(20行程度)を素で書き、停止条件とエラーハンドリングを試してみてください。そこから必要に応じてPlan-Executeや長期メモリを足していくのが事故の少ない順序です。
進展があったらこのブログで共有します。Plan-Executeを実業務に組み込んだ事例や、MCPと組み合わせたツール拡張についても、できたら定点観測の記事を書いてみたいと考えています。


コメント