※ この記事にはアフィリエイトリンクが含まれています。リンク経由で購入しても読者の皆さんに追加費用は発生しません。収益は本サイトの運営費に充てています。
Xアルゴリズムの最新版がxai-orgのGitHubリポジトリで公開されています。読んで導いた結論を先に書きます。Xアルゴリズムは15種類のユーザー行動の確率を予測し、重み付け合算でフィード順位を決める設計です。「いいねを稼げば伸びる」時代から「リプライ・引用・読了時間を取れる投稿が伸びる」時代に移りました。本記事ではXアルゴリズムのアーキテクチャを整理し、エンゲージメントを取りに行く投稿の組み立て方を解説します。
こんな方に読んでほしい
- Xを運用していて、伸びる投稿と伸びない投稿の違いを構造で理解したい
- 「いいね数より引用を取れ」という助言の根拠を技術的に押さえたい
- Xアルゴリズムの公開コードに何が書かれているか短時間で把握したい
- Grokが推薦に組み込まれた仕組みをアーキテクチャ視点で知りたい
XアルゴリズムがGitHubに公開された経緯
結論から書きます。Xアルゴリズムは2023年の旧Twitter時代に一度公開されました。2026年にはxai-orgが大幅に書き換えた新版を公開しています。Grokベースのトランスフォーマーモデルが推薦の中心に据えられた構造です。
透明性の確保と、研究コミュニティからのフィードバック獲得が公開目的とされています。広告主や投稿者にとっても、フィード露出のルールを構造的に理解できる価値は大きいです。
2026年公開のリポジトリ概要
リポジトリはgithub.com/xai-org/x-algorithmで公開されています。ライセンスはApache 2.0で、商用利用も改変も可能です。スター数は2万件を超えており、機械学習エンジニアと開発者から強い注目を集めています。
実装言語はRustが中心です。推論パイプラインの低レイテンシを意識した構成になっています。READMEには「For You」フィードの生成ロジックが書かれています。ユーザーがアプリを開いてから1秒以内に投稿が並ぶよう、サブミリ秒のルックアップを前提に設計されています。
2023年twitter/the-algorithmからの変化
2023年のtwitter/the-algorithmはSimClustersやTwHINが中心でした。これらは独自の埋め込み手法です。2026年版はそれらを廃止し、Grokベースのトランスフォーマーで埋め込みとランキングを一体化させた構造に変わりました。
手作業の特徴量設計が大幅に削減された点も大きな違いです。READMEには「全ての手作業の特徴量とほぼ全てのヒューリスティクスを排除した」と明記されています。学習済みモデルが特徴量設計を肩代わりする方針です。
Grokを開発するxAIが主導する理由
xAIはx.aiでGrokシリーズを開発する企業です。同じグループ内でフィード推薦と生成モデルが揃いました。推薦エンジン自体に大規模言語モデルの能力を直接組み込める体制になっています。Phoenix Transformerの「Grokベース」という記述は、この内製化の成果です。
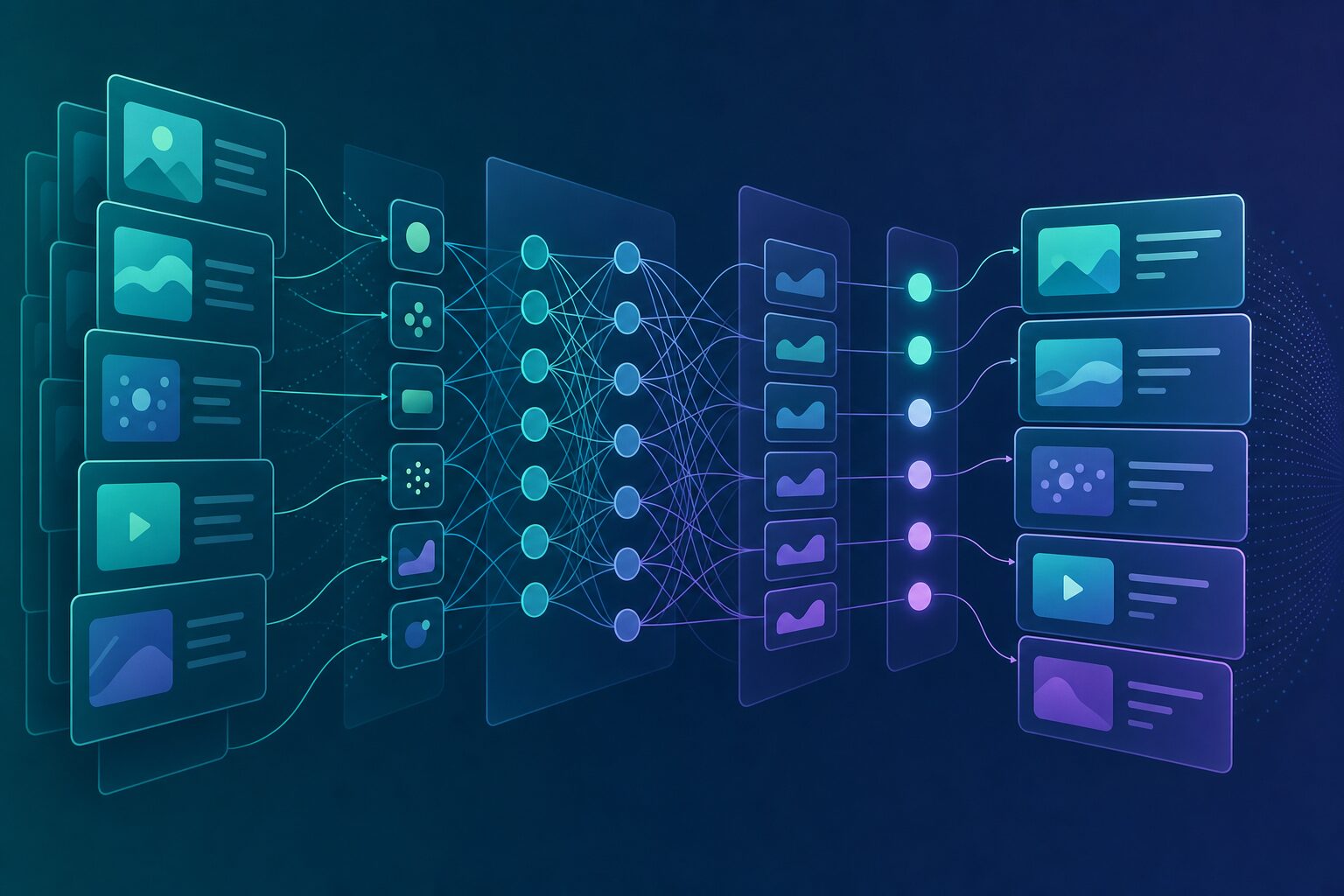
Xアルゴリズムのアーキテクチャ全体像
結論から書きます。Xアルゴリズムは「候補生成」「ランキング」「フィルタリング」の3段階構造です。候補生成では大量の投稿から数千件に絞り、ランキングで順序を決め、フィルタで除外候補を取り除いてユーザーに配信します。
ThunderとPhoenix Retrievalの二系統
候補生成は2系統に分かれています。1つ目はThunderで、フォロー中のアカウントの投稿を取得する系統です。Kafkaストリーミングでメモリ上に投稿を載せ、サブミリ秒のルックアップを実現しています。
2つ目はPhoenix Retrievalで、フォロー外の投稿を取得する系統です。こちらは「二塔モデル(two-tower architecture)」で実装されています。ユーザー側と投稿側でそれぞれ別のニューラルネットを使い、埋め込みベクトルに変換します。内積で類似度を測って上位を取り出す方式です。
Phoenix Transformer:Grokベースの重ランカー
候補が集まると、Phoenix TransformerというGrokベースのトランスフォーマーが各投稿のスコアを計算します。15種類のユーザー行動の発生確率を予測し、それらを重み付き合算した値が最終スコアです。
設計上のポイントは「候補同士が互いを参照しない」点です。各投稿のスコアはバッチ内の他投稿に依存しません。結果がキャッシュ可能で安定する設計です。同じ投稿は基本的に同じスコアになり、ユーザーごとの個性は、ユーザー側のコンテキスト埋め込みで反映されます。
Author Diversity Scorerと最終選別
スコア計算の後段で、Author Diversity Scorerが同一著者の連続を減点します。フィードに同じ人の投稿が並びすぎないよう調整する仕組みです。最終的にスコア順にソートして上位K件を選び、フィルタにかけてユーザーに表示します。
Phoenix RankerでXアルゴリズムが予測する15のアクション
Xアルゴリズムの心臓部はPhoenix Transformerが予測する15種類のアクションです。READMEから引用すると、ポジティブシグナルが11種類、ネガティブシグナルが4種類あります。それぞれに重みが設定され、合算が最終スコアになります。
ポジティブシグナル11種類
具体的な11種類は以下のとおりです。括弧内は対応するユーザー操作です。
- P(favorite):いいね
- P(reply):リプライ
- P(repost):リポスト(旧RT)
- P(quote):引用ポスト
- P(click):リンククリック
- P(profile_click):プロフィールクリック
- P(video_view):動画視聴
- P(photo_expand):画像拡大
- P(share):シェア
- P(dwell):閲覧時間(読了に近い指標)
- P(follow_author):その場でのフォロー
READMEでは具体的な重みの数値は開示されていません。リプライや引用、読了時間といった「深い関与」を示す指標は、いいねよりも強い学習信号として扱われる設計が一般的です。Xの過去の発表でも、リプライと引用の重みがいいねの数倍に設定されていた経緯があります。
ネガティブシグナル4種類
残りの4種類は減点要素として動きます。負の重みが掛かるため、これらの確率が高い投稿はスコアが下がります。
- P(not_interested):「興味がない」のタップ
- P(block_author):著者をブロック
- P(mute_author):著者をミュート
- P(report):投稿を報告
READMEには、ブロック・ミュート・報告のような負のアクションには負の重みが掛かると明記されています。ユーザーが嫌いそうなコンテンツを押し下げる仕組みです。投稿者のスタイル自体が「ブロックされやすい」と学習されると、その後の表示が抑制される構造です。
スコアの合算式
最終スコアは以下の単純な線形和で計算されます。
Final Score = Σ (weight_i × P(action_i))線形和は実装も理解もシンプルです。重みの大小が結果を支配するため、Xが内部でどの行動にどれだけ重みを置いているかが運用の核心になります。公開コードからは具体的な重み値は読めません。実投稿の伸び方から逆算するしかない部分です。
Xアルゴリズムでエンゲージメントを取りに行く投稿設計
結論から書きます。Xアルゴリズムでスコアを取りに行く投稿は、いいねよりリプライ・引用・読了時間(Dwell)を呼ぶ構造に組み立てます。下の3つの設計原則は、公開された15種類の予測ターゲットから直接導けます。
Replyを誘発する投稿パターン
リプライを取るには、読者が自分の経験を返したくなる「問い」を本文に置きます。質問形式の文末、対立軸を提示する書き方、共感を呼ぶあるある文の3パターンが鉄板です。
具体例は以下のとおりです。「ChatGPTとClaude、皆さんどっち使っていますか」のような直接的な質問は最も単純で効きます。「自動化と手作業、現場で判断する基準は何ですか」のような複雑な質問は、リプライの内容が深くなる傾向があります。
注意点もあります。質問ばかりの投稿は「アンケートばっかり」と認識され、Dwellやプロフィールクリックが下がります。質問は週2〜3回程度に抑える運用が無難です。
QuoteとDwellを取りに行く構造
引用ポストは「自分の意見を添えて広めたい」と思わせる投稿で発生します。明確な主張、業界全体への提言、賛否が割れる立場の3パターンが効きます。
Dwell(閲覧時間)を取るには、本文の情報密度を上げることが重要です。固有名詞・数値・期日を本文に含めると、読者は内容を確認するために投稿に留まります。「Anthropicが$200M、OpenAIが$4B」のような具体数字の連打が、読了時間を稼ぐ典型例です。
長文化を狙うときは、Xの長文投稿機能(Premium以上)か、スレッドで構造化する方法を選びます。1投稿が長すぎると離脱が増えるので、200〜400字を1つの単位として、複数連続させる構造が安定します。
動画と画像の比重
Phoenix Rankerにはvideo_viewとphoto_expandが独立した予測ターゲットとして含まれています。動画再生と画像拡大が、それぞれ別のスコア要素として効くわけです。テキストのみの投稿に比べて、動画付き・画像付きの投稿はスコアを取りに行く余地が多いです。
動画は短くて構いません。15秒程度のループでも、再生回数(video_view)が稼げます。画像は1〜4枚、テキストでは表現しづらい比較表や図解を貼ると、photo_expandを取りやすくなります。
Xアルゴリズムが減点するNG行動
結論から書きます。Xアルゴリズムでスコアを下げるのは「スパム認定」「同一著者の連投」「ブロック・ミュート率の高さ」の3要素です。投稿の中身以前に、これらが発火すると配信そのものが絞られます。
スパム・低品質判定の基準
READMEには「削除済み・スパム・暴力・グロといった投稿を除去するVFFilter」が明記されています。フィルタは候補生成後・選別後の両方で動きます。誤検知でフィルタにかかると、その投稿はそもそも配信先のフィードに乗りません。
スパム判定を避ける基本は、外部リンクの貼りすぎを控えることと、同じ文面の連投をやめることです。アフィリエイトリンクの大量貼りつけや、同じハッシュタグの連投も判定を悪化させます。
著者の偏りを減点するDiversity Scorer
Author Diversity Scorerは、同じ著者の投稿がフィード上位に並ばないように減点します。短時間で大量に投稿しても、後半の投稿はスコアが落ちる仕組みです。連投の効果は逓減します。
「1日に何十回も投稿すれば伸びる」という運用は、このスコアラーで打ち消されます。投稿頻度より、1投稿あたりの完成度を上げる方向が、結果としてスコア合算で得をする設計です。
ブロック・ミュート・報告の累積
ブロック率やミュート率は、Phoenix Transformerが直接予測する負の信号です。アカウント単位でこれらが高い水準を維持すると、投稿のスコアが構造的に下がります。煽りすぎ・絡みすぎ・炎上狙いはアカウント自体の評価を毀損するため、長期運用では避けたい挙動です。
Xアルゴリズム時代の投稿運用チェックリスト
結論から書きます。Xアルゴリズムを踏まえた投稿の作り方は、投稿前のチェックと投稿後の動きの2フェーズで管理します。以下のチェックリストは、公開コードから読み取れる優先順位に沿って組み立てた実用版です。
投稿前に確認する5項目
- 本文末に質問・主張・対比のいずれかが含まれているか(Reply・Quote誘発)
- 固有名詞・数値・期日が3つ以上含まれているか(Dwell誘発)
- 動画または画像が添えられているか(video_view・photo_expand獲得)
- 同じハッシュタグ・同じ文面の連投になっていないか(スパム判定回避)
- 過度な煽り表現や攻撃的な言い回しがないか(ブロック・ミュート回避)
5項目のうち、最重要は1つ目と2つ目です。質問または主張がない投稿は、いいね止まりで終わりやすいです。固有名詞と数字の連打は、Dwellを稼ぐ最も簡単な手段です。
投稿後30分の動きが分かれ目
Xアルゴリズムは投稿後30分以内のエンゲージメント密度を強く重視する設計と言われています。Phoenix Transformerはリアルタイムに学習データを更新します。初動のリプライ・引用が伸びると、フィード露出が拡大する好循環が発生します。
初動を取るには、投稿時間帯を平日7〜9時または18〜20時に合わせる運用が定石です。リプライが付いたら早めに反応すると、会話の連鎖がスコアに乗りやすくなります。
記事との連動で組むなら
ブログ記事とXを連動させるなら、記事冒頭で読者の悩みを1文で提示します。Xの投稿側で同じ悩みを書いて、記事に誘導する構造が組みやすいです。AIエージェント実装ガイドやCursor 3の解説記事のように、悩みから入って解決を提示するパターンが効きます。リプライと引用が取りやすい構造です。
まとめ:Xアルゴリズム公開コードから学ぶ運用設計
Xアルゴリズムの公開コードを読んで分かったことは、フィード推薦が15種類の行動予測の重み付け合算で動いていることでした。いいねを稼ぐ最適化から、リプライ・引用・読了時間を取りに行く最適化に運用の軸を移すべき設計です。動画や画像の独立スコア、ネガティブシグナルの減点、Author Diversity Scorerまで論点は複数あります。すべて投稿の組み立て方を変える理由になります。
公開コードはRustで実装され、Grokベースのトランスフォーマーが推薦の中心に据えられています。手作業の特徴量設計はほぼ撤廃され、学習済みモデルが特徴量と推薦を一体で扱う構造です。
具体的な重み値は公開されていません。投稿の伸び方を観察しながら、自分の運用の何が効いているか確かめ続ける作業は今後も必要です。できたら定点観測の結果を整理して、また書きます。


コメント